I recently wrote a little tool that implements a simple algorithm proposed in this Google article. The idea is you can analyze your codebase and score each source file with a "bugginess".
The problem we are trying to solve here is to mitigate the common "Look's good to me" when code reviewing.
It is easy to understand why this problem exists. As any codebase and team grows, this problem grows in turn. With many developers changing source code over time, the learning curve for the codebase becomes more difficult. This problem can arise when the code reviewer does not fully understand the language, pattern, organization, structure, and history of the code.
Code history holds a ton of knowledge. We humans would have a hard time holding the full history of a codebase in our head though... so let's automate it.
If we can figure out how buggy a source file is, a code reviewer can be confident in knowing how dangerous their "Look's good to me" comment will be. For example, if a file's bugginess score is very low, the reviewer can quickly look over the changed content and know that this file has rarely caused issues in the past. Although, on the other hand, if the file has a high score, the developer might want to ask for more developers to review the code being changed.
So how can we figure out the score of a source file?
In the original implentation, the algorithm used purely git commit messages to figure out if the files being changed were related to a bug fix. In my organization, we do not have that luxury. Our commit messages have evolved over time and we have used other tracking tools to communicate the purpose of code changes. Thankfully we have years of history in our tracking tool. And each story tied to code changes has a "type" we can filter by.
Now we have our commits related to bug fixes.
In order to score each file, we could just count the number of commits that changed said file. Although, a Google engineer came up with a fancy formula for value-over-time which we will use instead.
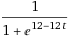
The commit time is normalized by treating 0 as the first commit time and 1 as the current time. For each commit, this score is added to the changed file's total score.
As for the implentation, I used local git commands instead of hitting Github's API for two reasons:
- Speed of commit searching and information retrieval
- Did not want users to have to hassle with another API token
After building the data, I sort it and output the result to a CSV file for ease of visualization.
I simply dragged it into Google Drive and created a chart in seconds, which showed where our dangerous code lived.
Check out the code!
Future Ideas
- Integrate more tracking tools
- Use Github Issues as a source of data
- Allow for custom value-of-time formulas
- Modularize the commit gathering (choose local git, github, bitbucket)